Stylometry Study: Detecting Cross-Market Profiles
Researchers analyzed the literary style of darkweb vendors to identify vendors using different identities.
Using stylometry, researchers analyzed thousands of vendor identities on four darkweb marketplaces and linked more than 700 identities. The study involved the collection of information nodes, which included vendor profiles from four defunct marketplaces, including Valhalla (522), Dream Market (2,547), Evolution (1,650), and Silk Road 2 (681).
attributed heterogeneous information network schema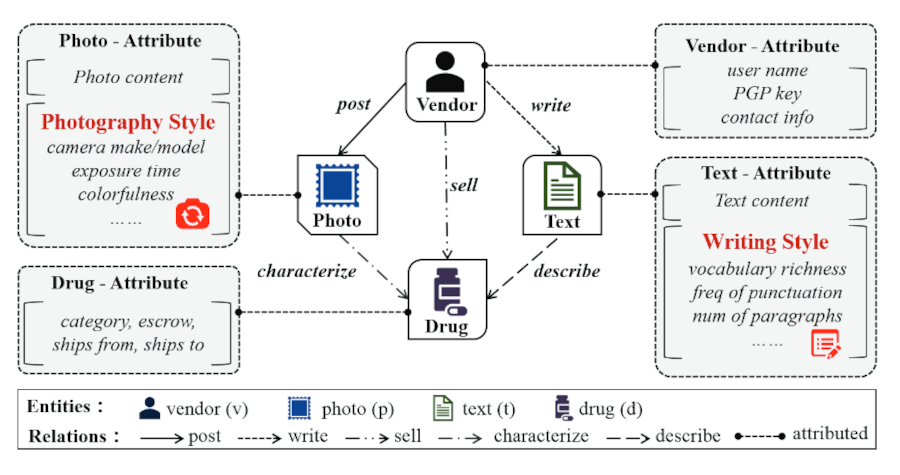
The study builds on previous work that analyzed only the pictures uploaded by vendors to link separate identities. The paper is way too long to include here, but I will attach it in pdf and HTML form at the bottom of the page.
To start, the researchers collected several sets of features from the vendor profiles.
Posted text and writing style
“To finger-print a vendor based on his/her posted texts, we consider both his/her posted text content and writing style. For text content, we propose to exploit doc2vec to convert each text of variant size into a fixed-length feature vector. For writing style, we propose to extract multi-scale stylometry features at three different levels: lexical, syntactic, and structural.
- Lexical features can be further divided into character-based and word-based groups to capture stylistic traits. At this level, we extract:
- number of characters (all, upper, or lower case),
- number of digits/white spaces/special characters (e.g., ‘%,’ ‘$’, ‘@’),
- number of words,
- average word length, and
- Vocabulary richness.
Meta-paths built for drug trafficker identification.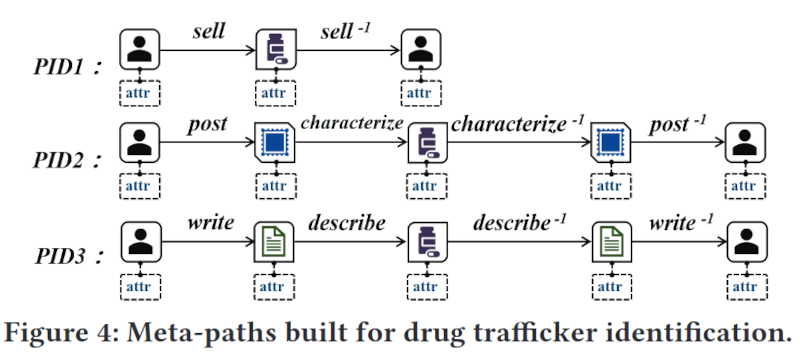
Vocabulary richness is helpful to gain an understanding about an author’s use of vocabulary and the complexity of the author’s language.”
Syntactic features
“Syntactic features capture the writing style from the sentence structure. In this category, we adopt four types of features:
- frequency of punctuation (e.g., ‘.’, ‘!’, ‘?’),
- frequency of function word (e.g., for, to, the),
- number of sentences beginning with a capital letter, and
- frequency of parts-of-speech n-grams extracted by using Stanford log-linear parts-of-speech tagger.”
Structural features
“Structural features represent the way an author organizes the layout of his/her posted text. We consider the following four types of structural features:
- the total number of paragraphs,
- indentation of the paragraph,
- whether there’s a separator between paragraphs, and
- the number of words/sentences/characters per paragraph.
For each posted text by a vendor, we then concatenate its converted feature vector representing the posted text content and the feature vector describing its writing style as an attribute associated with this posted text for further analysis.”
A similar process is described for other feature sets, such as the data associated with a vendor’s product listing images.
“After the feature extraction, each vendor, drug, text, or photo is associated with its related attributes represented by a feature vector. For example, a vendor is associated with attributes of username, PGP key, and contact information represented by its corresponding feature vector, while a photo is associated with attributes of its photo content and photography style represented by its concatenated feature vector.”
Results
“…For the detected cross-market vendor pairs, we further sample 798 pairs and validate them using conclusive pieces of evidence, including (1) manually reading the product descriptions (e.g., sometimes the pair themselves admit in their posts about their other accounts), (2) examine the type of drugs they sell, and (3) check vendor reviews. Among these 798 detected cross-market pairs, 726 pairs (90.09%) are with high confidence that they are the same individuals and 22 pairs are uncertain (2.76%).”
I felt like this one might have been obvious...
Overall, I think some critical information is missing from the study. We do not know how many separate vendor identities are pairs with similar usernames (i.e., not hidden profiles). If the researchers successfully identified accounts secretly operated by the same entity, that would be much more significant than identifying multiple accounts openly used by the same entity.
Thanks to court documents, we know that law enforcement sometimes puts in the work to find alternate vendor profiles during an investigation. In some cases, they use the “verified feedback” sections found on some marketplaces. In some cases, such as the AREA 51/Dark Apollo case, they look for accounts with matching PGP keys. You have cases like the Canna_Bars case where investigators used stylometry to support their accusations. On the other hand, I regularly find cases where a vendor’s account on X market is the focus of the case but the vendor has an account on a different market with a similar number of transactions or history (I can understand not bothering to add profiles with two transactions to a criminal complaint).
In general this is not anything new; stylometry is not going to be the one thing that leads to someone’s arrest. Stylometry might make an appearance in a case but it will be supplemental to other investigative methods or perhaps part of a narrative crafted for parallel construction.
It is interesting to see the potential for bulk collection of matching vendor profiles.
AFAIK, with enough material to work with, investigators can almost always match Person X to Alias Y. Intentionally masking Person X’s literary style when posting as Alias Y might help prevent a match when there is a combined total of two sentences. But if you are leaving thousands of words online on multiple profiles, I think it is a guarantee that a machine could identify unique (or unique enough) literary patterns.
Your Style Your Identity: Leveraging Writing and Photography Styles for Drug Trafficker Identification in Darknet Markets over Attributed Heterogeneous Information Network: pdf, html